Why
Some days ago I enrolled in my first topcoder development challenge and it is basically a tutorial challenge where we need to install HPVertica DB, capture a set of tweets and based on $HPQ tag, use the HP Idol platform, which has an API to perform sentiment analysis over a tweet text content.
With that in mind I decided to start this challenge with Play Framework to learn a little bit and see how fast I could create this WebApp from scratch without know the tool. Beside that, I have read about play framework and it seems to be a very powerful tool which I could easily plug different technologies and keep focused in my development. It provides you a sort of minimum viable architecture for your system. In addition, another reason to pick this technology is because I can use Java, which was one of the requirements of the challenge.
The challenge - https://www.topcoder.com/challenge-details/30048480/
"Here are the steps to participate in the HP Haven Twitter Analysis Tutorial challenge:
- You’ll be creating a Java application which accesses Twitter data for the Hewlett Packard stock symbol tag “$HPQ”, performs sentiment analysis on this data, and loads the raw social feed and sentiment data into the Vertica database. The application should also display some kind of visualization about how sentiment is changing over time or by topic. The application should extract enough Tweets that the Sentiment Analysis shows some depth/variation – at least 1000 Tweets, but more would even be better.
- You have creative license about what kind of application to create. You may create a mobile, web, or desktop app.
- Your application should connect to the IDOL OnDemand platform to perform the Sentiment Analysis on the Twitter data related to the tag $HPQ. The Sentiment Analysis results should be stored in your locally configured version of Vertica. Sample Java code to connect to IDOL OnDemand is attached to the challenge. Sample code can also be found on the IDOL OnDemand Community site.
- This is a tutorial challenge. Your code should be clear and well documented.
- You should produce a blog post about your application.
- You should produce a screensharing video which explains your code and how to set up and connect to a Vertica database.
- There should be some kind of visualization in your app which displays the Sentiment Scores related to a topic and/or time dimension.
- We're currently running a Sweepstakes challenge which walks through the Vertica setup on a local VMWare instance. We're also attaching a Vertica lab manual which describes how to add users, create schemas, and load data into the system. It assumes, however, that you have the Vertica Virtual Server instance installed and locally available."
How
Tools and Frameworks
Java; Play Framework; Spring; Spring Data; Hibernate; WebSockets; Akka; Twitter4J Search & Stream API; Redis; HPVerticaDB; HPIdol OnDemand API; Twitter Bootstrap 3; JQuery 1.11; Highcharts.
Application design
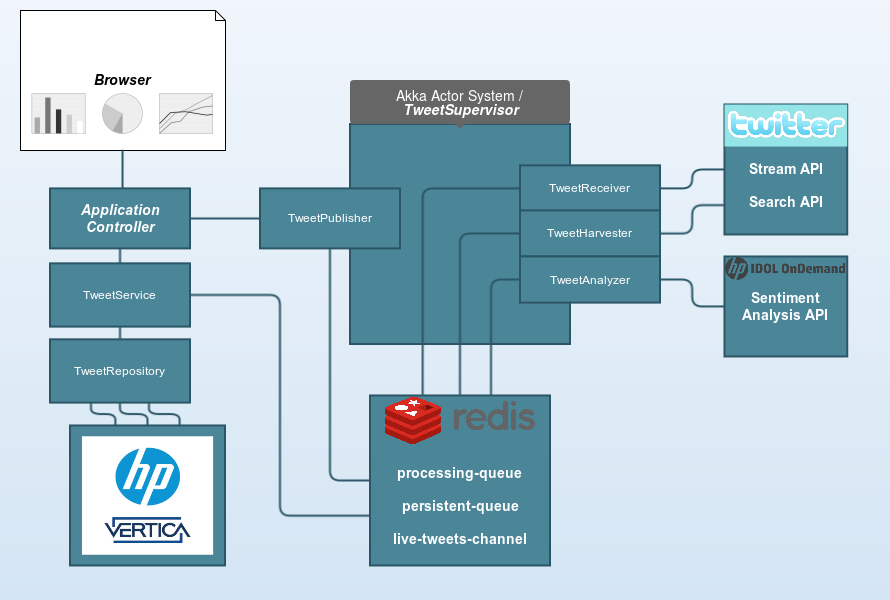
Screencast
Design notes
Twitter API
Stream - https://dev.twitter.com/streaming/overview:
"The set of streaming APIs offered by Twitter give developers low latency access to Twitter’s global stream of Tweet data. A proper implementation of a streaming client will be pushed messages indicating Tweets and other events have occurred, without any of the overhead associated with polling a REST endpoint."
In this case I am using the public stream API, it is enough to receive the tweets in real time.
Search - https://dev.twitter.com/rest/public/search:
"The Twitter Search API is part of Twitter’s v1.1 REST API. It allows queries against the indices of recent or popular Tweets.."
Here I am just using a GET method for twitter.com/search?q=%MY_HASH_TAG% URL to search and grab the tweets with the hashTag param.
Twitter4J - http://twitter4j.org/en/index.html
It is an unofficial library to connect to twitter APIs. You can check the code examples here and more code examples To connect to API you will need some oauth keys and consumer keys.
HPIdol OnDemand API - https://www.idolondemand.com/
Setiment Analysis API - http://www.idolondemand.com/developer/apis/analyzesentiment#overview
"The Sentiment Analysis API analyzes text to return the sentiment as positive, negative or neutral. It contains a dictionary of positive and negative words of different types, and defines patterns that describe how to combine these words to form positive and negative phrases."
The hello world in java for HP Idol API can be found here.
Redis - http://redis.io/
Processing Queue:
This queue keeps all the tweets that are in processing phase. For instance, when we receive a new tweet from Twitter Stream API or when we found a set of tweets in Twitter Search API, they are placed in this queue to be processed later.
Processing action here means: we need to parse the tweets, extract the relevant information and send it to HP IDOL API to do the analysis for each one of them. The result of this phase will be placed in another queue (persistent-queue).
'The tweets are saved as String in redis queue.'
Persistent Queue:
This queue keeps all the tweets that were processed, analyzed and now are ready to be stored in VerticaDB with
sentiment score.
Live Tweets Channel:
This channel publishes all the tweets that were processed and analyzed to the subscribers of this channel. It is just a Redis pubSub system, you can learn more about it here.
In this app it is really useful, cause I would like to see the sentiment analysis in real time for all tweets that comes from Twitter Stream API. So, right after analyze it, I just send the results to this channel which will automatically publish this content to every subscriber. The subscriber in this case is an Akka Actor Reference which was created by a websocket connection request, that happens when you open the open the index page with the live tweets chart.
HP Vertica DB - https://my.vertica.com/community/
You can download the HP Vertica community edition here It is a relational database optimized for large-scale analytics. "It is uniquely designed using a memory-and-disk balanced distributed compressed columnar paradigm, which makes it exponentially faster than older techniques for modern data analytics workloads. HP Vertica supports a series of built-in analytics libraries like time series and analytics packs for geospatial and sentiment plus additional functions from vendors like SAS. And, it supports analytics written using the R programming language for predictive modeling." More details about the technology can be found here.
Akka Actor System
Akka is a framework which provides the set of right tools to build high-scalable and fault-tolerant systems using a Actor System model. You can easily write parallel, concurrent, event-driven programs. To learn about Akka check it out. In this project I decided to use Akka to create microservices that would connect with external API`s. In this case my 4 actors play different roles and they are managed by one supervisor. The idea here is to have a service manage that would orchestrate the messages and actions in my actor system.
Tweet Receiver:
An Actor Reference which connects to Twitter Stream API using Twitter4J library and listen to tweets from API.
For each new tweet, the actor parses the content and push the result into redis processing-queue.
After that it sends a 'Read' message to the TweetSupervisor.
Currently I am starting only one instance of this actor for the tag+language that I want to receive the tweets.
Later I can easily change to create one instance per tag or something like it.
Tweet Harvester:
An Actor Reference which connects to Twitter Search API to perform the tweet search based on the tag+language.
It can easily reach the Twitter requests rate limit, so I place this Actor to run every 15 min whatever happens
with it. This setup can be found in TweetSupervisor that we will cover in the next sections. After parse the tweets found
it sends a 'Read' message to TweetSupervisor.
Tweet Analyzer:
Another Actor Reference which receives a 'Read' message from TweetSupervisor to start reading tweets from processing
queue to send it to HP Idol Sentiment Analysis API. The requests to HP API are synchronous and each result is parsed, appended to the original tweet, sent to the persistent-queue and published to the live-tweets-channel.
N instances of this actor will be created be the supervisor, after each instance execute the job, it finalizes itself.
Tweet Publisher:
It s an special Actor Reference which is not managed by TweetSupervisor. I`m using this Actor to
handle the tweets published in live-tweets-channel and send it directly to the client.
Cause in the client side we have a scatter chart which shows in real time the tweet sentiment analysis.
For this, was necessary to open a websocket connection per client, each connection is handled by an Actor Reference (Tweet Publisher) that subscribes the redis channel.
Tweet Supervisor:
It handles two type of messages, Read and Start. This messages are java objects and when an Actor Reference (instance) receives a message that it can handle, it simply execute some action based on it.
So, when the TweetSupervisor receives a Start message it starts two actor instances; TweetReceiver and TweetHarvester.
If the supervisor receives a Read message, it starts a new instance of TweetAnalyzer actor.
Service, Repository & Controller
Tweet Service:
Starts the Akka Actor System with the TweetSupervisor, Runs a scheduled job in order to persist
the analyzed tweets, provide some methods to find tweets in TweetRepository.
Tweet Repository:
It is a spring data repository which provides a set of actions to be done in the db. For instance, findAll, findBySomeProperty, and so on.
Application Controller:
Main controller which receives the HTTP requests, handle and return a Result, which can be a simple html page, a WebSocket connection or JSON response. Available Methods:
-
Live tweets
GET / controllers.Application.liveTweets()
-
Timeline
GET /timeline controllers.Application.timelineTweets()
-
Pie chart
GET /pie controllers.Application.pieTweets()
-
Web socket connection
GET /ws-tweets controllers.Application.wsTweets()
-
Tweets by sentiment type
GET /tweets/:sentiment controllers.Application.tweets(sentiment: String)
-
Tweets statistics
GET /statistics controllers.Application.statistics()
Application Installation
-
OpenJDK1.5: sudo apt-get install openjdk-7-jdk -
Play Framework Installation- https://www.playframework.com/documentation/2.3.x/Installing -
Import the project - IntelliJIDEA- https://confluence.jetbrains.com/display/IntelliJIDEA/Play+Framework+2.0 -
HP Vertica DB- https://my.vertica.com/docs/5.0/PDF/Installation%20Guide.pdf -
HP Idol Keys- http://idolondemand.topcoder.com/
Place your keys in the application.conf file under twitter-analyst/conf/ folder
// HP IDOL Platform
hp.idol.analyze.sentiment.uri="https://api.idolondemand.com/1/api/sync/analyzesentiment/v1?text=%TWEET%&language=%LANG%&apikey=<IDOL_API_KEY_HERE>"
Twitter API Keys- http://www.androidhive.info/2012/09/android-twitter-oauth-connect-tutorial/
Place your new keys in the application.conf file twitter-analyst/conf/ folder
// Twitter 4J OAuth
twitter.oauth.consumerKey=""
twitter.oauth.consumerSecret=""
twitter.oauth.accessToken=""
twitter.oauth.accessTokenSecret=""
this tutorial shows you how to get the twitter keys and tokens.
Connecting to Vertica
Make sure you are using the persistence.xml with PostgreSQLDialect and setting your default schema name, like
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="defaultPersistenceUnit" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<non-jta-data-source>DefaultDS</non-jta-data-source>
<properties>
<!--<property name="hibernate.hbm2ddl.auto" value="none" />-->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/> // Postgre Dialect
<property name="show_sql" value="true" />
<property name="format_sql" value="true" />
<property name="use_sql_comments" value="true" />
<property name="hibernate.default_schema" value="public"/>
</properties>
</persistence-unit>
</persistence>
After that, you need to include in the classpath the vertica-jdk5-6.1.0-0.jar which is located at twitter-analyst/lib/ folder of the project.
You need to update the Vertica IP address, db-name, schema-name into application.conf file under twitter-analyst/conf/.
// VerticaDB
db.default.driver=com.vertica.jdbc.Driver //This is the driver class that we use to connect to Vertica.
db.default.url="jdbc:vertica://<your.db.ip.addr>:5433/<db-name>"
db.default.user=dbadmin
db.default.password=""
db.default.schema="<schema-name>"
db.default.jndiName=DefaultDS
Creating the Model
Play Framework can apply your sql scripts to the database, however I could not use this feature. I got some issues with the Postgre dialect here. So, in this case I suggest you to copy the file from
- /twitter-analyst/conf/evolutions/VMart/ddl/1.sql
and execute it directly in VerticaDB. Make sure your schema is the same that we use in these files, or just replace it with your schema name.
-
Loading the DataUnder the same folder you will find the dml/2.sql which contains 10K+ inserts of tweet with $HPQ tag, you can load it into your DB. Make sure the schema name is right. -
Connecting to RedisJust place the Redis IP address in the application.conf file
// Redis
redis.host="<your.redis.ip.addr>"
Starting the Application
After install the VerticaDB, Redis, Generate you keys for Idol and Twitter, Import the project, you just need
to go in Run -> Run Play 2 and wait for the application bootstrap.
If you do not see any tweets in live tweets chart, just tweet in your own account using the tag $HPQ and you will see it in the live chart. Or just set the property 'tweet.analyst.tags' in application.conf file to use a trend hashtag and you will receive a tsunami of tweets.
Here we have two examples of positive and negative tweets in the live tweets chart.
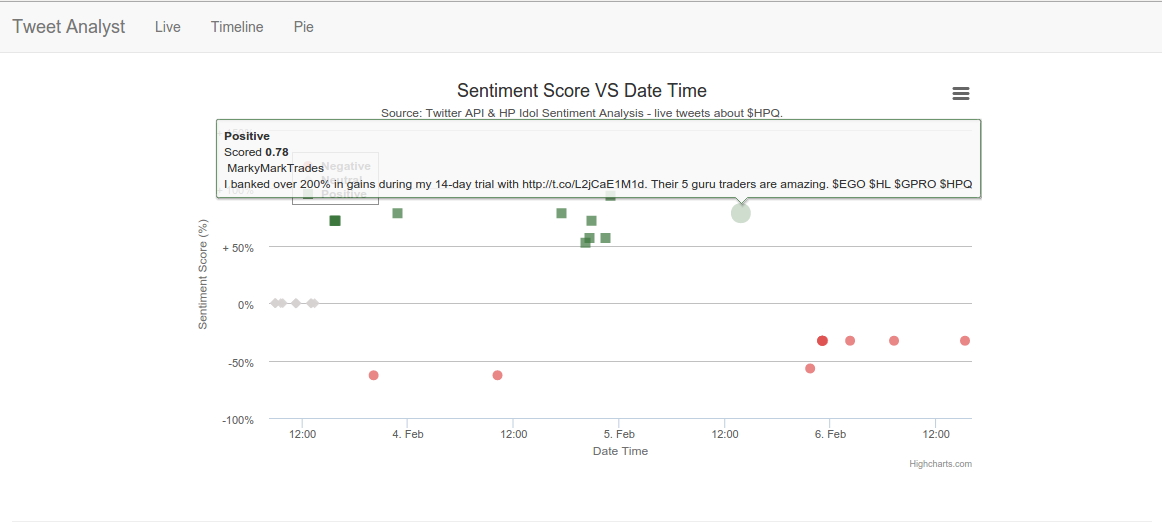
- The green dots are all tweets considered positive, which means they received a score > 0 from HP Sentiment Analysis API.
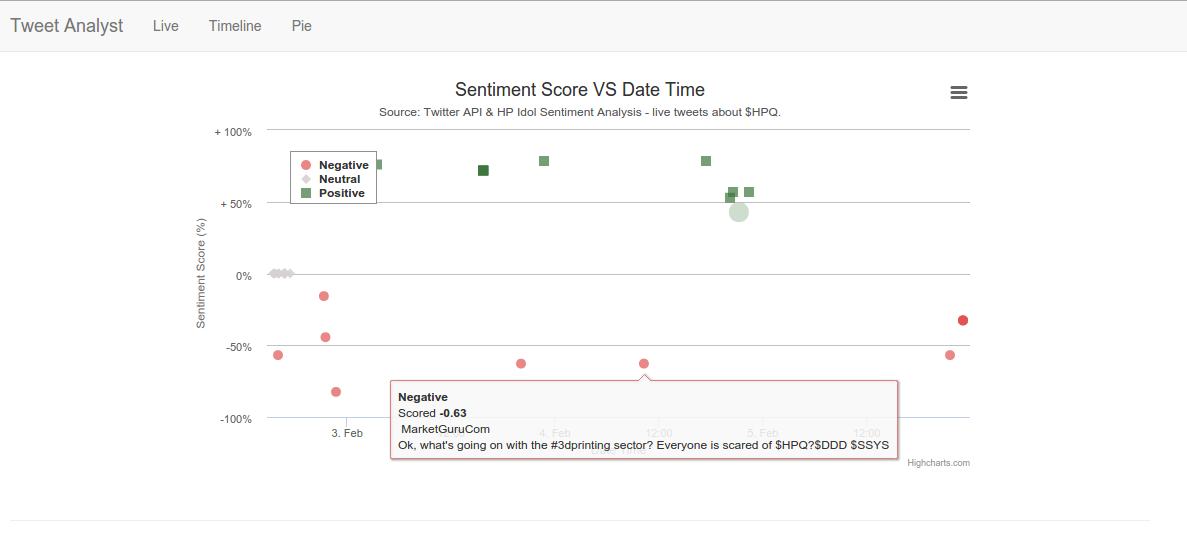
- The red dots are all tweets considered negative, score < 0.
- The gray dots are all tweets considered neutral, score = 0.
To see the sentiment score information and the tweets content you can navigate between the charts Live, Timeline and Pie. Each one of them will be reloaded completely from scratch every time you hit the page. Place the mouse over the dots to see the content.
- Live: tweets analyzed in real time and placed in the chart.
- Timeline: all the tweets analyzed and stored in the db can be filtered by date range.
- Pie: Tweets sentiment share.
Final Thoughts
It was my first application using Play Framework, Akka and HP Idol API. I have to say it was really easy and fast to setup and create the app. The more important here was that I could use my time to focus on what features I would create instead of spending time on the minimum viable architecture.
The Akka is a great framework to create microservices without pain. I would like to had developed unit and integration tests, mainly for the actors. Due to the time constraints, unfortunately, I was not able to do it. But I will. In a near future. I do want to see and learn how easy/complex is to test the actors and the message flow.
The Sentiment API was another great tool. I really want explore the other APIs from HP Idol OnDemand, for sure. In this challenge I could see that we can create nice apps just plugin into different APIs around the world. We can get a ton of data from social media APIs (Twitter Stream, awesome!! your app receiving tweets near real time). Grab and send it to be processed by whatever open and free service you find out on the internet. Put together the pieces and wala! You have a nice app running.
I think that`s all people.
Feel free to contribute, share your opinion about the design decisions and technologies.
Thanks!

[]`s,
Felipe Forbeck.

Comments
comments powered by Disqus