Motivation
Vanhack promoted a hackathon for programmers, designers and digital marketers who want to show their skills to Canadian technology companies. Vanhack is a startup that helps skilled IT people from all around the world to get awesome jobs in Canada. This was the first hackathon they promoted and they already said that we will have more.
For this edition we had companies such as AxiomZen, Hootsuite, Shopify and many other. You can take a look here. Each company proposed one or more challenges for back-end, front-end, UX Designers, etc. I've developed a REST API in Java with Neo4J for the challenge proposed by Hootsuite.
I really liked the challenge which you can see the basic description bellow:
- Build a system using graph DB to represent the microservice dependency graph.
- Imagine thousands of microservices calling each other on different API endpoints using REST:
- How would you know which service depends on another?
- How often API calls are being made from one service to another?
- Does one service always call all endpoints of another service, or usually just one or two?
It was an open ended challenge.
I decided to move forward with this challenged because I would like to use a graph database, mainly Neo4J and learn a bit more. I already did some small apps and proof of concepts with it in the past, but then I never touch it again.
Problem
The first thing was to decide in which language I would develop the API. I was wondering if I should use Java or Python.
For Python I could use Tornado, which is web framework and asynchronous networking library. Pretty easy to install and use. Python usually I write less code than Java to get the things done and I already created a REST API with Python and Tornado, but never using a graph db.
For Java I could use Play Framework which is also a web framework built on top of Akka. I already created an App using Play Framework and it was very productive and easy to use. You can check it here. Also I could use Spring Boot which I've used in the past in some consulting projects and you can enable maven libraries in your project to make it a web project, standalone app and so on.
Then I started thinking about how Neo4J would communicate with this two languages and, fortunately, it has official drivers for both languages: Java & Python. After some research I thought it would be good to use Java. Mainly because it has more options, besides the native drivers, to integrate with Neo4J. For instance: Spring-Data-Neo4j, Neo4j's Embedded Java API, JPA and JDBC.
I thought that I could easily use Spring-Data-Neo4j with Spring-Boot and start the App with a few lines of code, because spring-data provides that magic crud interface for repositories that allows you to easily access your persistence layer. So, I just decided to move forward with Java and Spring-Data-Neo4J. Assuming that I could try another approaches to integrate with Neo4j is something else wasn't working as expected.
Solution
Vacuum is the REST API which allows you to understand the dependency graph of your microservices architecture.
It is based on Swagger.io, you can just submit the URL of your swagger documentation and Vacuum will parse it and create the Service-Endpoint graph as you can see in the image bellow.
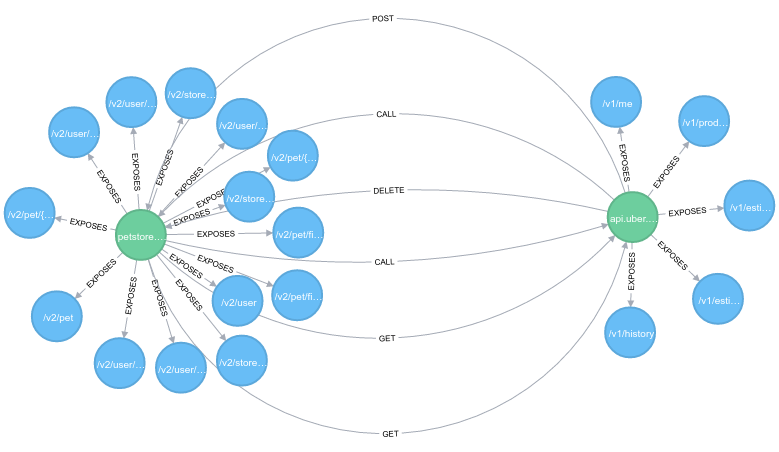
Nodes
-
Service: is the green node which represents the service host name. It is captured from Swagger API document. For Neo4J it is calledLabel. One node can have multiple lables. You can picture it as a node type. It is important to define the label/type for your nodes because it helps you to perform more interesting queries. The nodes with this type will have two properties:hostanduuid, in which host is the name of the host and uuid is generated for each new service registered in the system. -
Endpoint: is the blue node which represents the service endpoints. It is also captured from Swagger API document. It is a label and it has the propertypath, which is the path that the endpoint is exposing, for instance/v1/users/{id}.
Relationships
-
EXPOSES: it is a type/label which defines the relationship between two nodesServiceandEndpoint. It is an edge fromServicethat points toEndpointnode. It is also built based on swagger spec. With this we can see which endpoints each service is providing. -
CALL: it is a relationship created when you send a request to Vacuum API that reflects the call from service A to B. This relationship contains a property calledcount, every registered call from A to B,countis incremented. With that you can keep track of the number of calls from A to B. -
POST,GET,DELETEand other HTTP methods: are directed relationships created between two services A and B or B to A. It depends on which service is calling. We might have multiple relationships here because we can call the same service in different endpoints with different http methods. So, if service A calls a endpoint/v1/testusing methodGETVacuum will increment theCALLrelationship and create a new one from A to B calledGET, if it already exists we also increment thecount. Vacuum also stores in the relationship thepaththat is being called. In this casepathproperty would be populated with/v1/test.
Examples (Node--Relationship-->Node):
- Event 1 A calls
GET/v1/test on B:- (Service A)---(GET {path: /v1/test, count:1})--->(Service B)
- (Service A)---(CALL {count:1})--->(Service B)
- Event 2 A calls
DELETE/v1/test on B:- (Service A)---(DELETE {path: /v1/test, count:1})--->(Service B)
- (Service A)---(CALL {count:2})--->(Service B)
Registering your service
The first step is to register your microservice in the Vacuum API, for that you need to send a post request to /v1/microservices passing the swagger url of your API.
Creating a Service-Endpoint graph based on a Swagger URL
POST <host>:8090/v1/microservices -H 'Content-Type: application/json' -d '{"swagger_url": "<the_swagger_url>"}'
Registering a call from service A to service B
Once you have registered your service you can fire a POST request to Vacuum API when your microservice A is calling B. The request needs to be populated with the details about the call from A to B. These are parameters that need to be sent in the request which represents the event call from A to B:
- origin_host: The host name from service A
- method: The HTTP method that is being called on service B
- target_host: The host name from service B
- target_path: The endpoint that service A is calling on B
POST <host>:8090/v1/requests -H 'Content-Type: application/json' -d '{"origin_host": "api.uber.com", "method": "POST", "target_host": "petstore.swagger.io", "target_path": "/v2/user/login"}'
After that, Vacuum will create the relationships between both services considering the information you have provided in the request. Both services need to be registered in the Vacuum API.
Basic Queries
These are the basic queries that I have implemented that you can use to get more information about the calls that your services are executing.
Get all microservices which contains term user in ther endpoints
GET <host>:8090/v1/microservices?path_term=user -H 'Content-Type: application/json'
@Override
public List<Microservice> findMicroservicesByPathTerm(String term) {
List<Microservice> microservices = new ArrayList<>();
Driver driver = connector.getDriver();
HashMap<String, Object> params = new HashMap<>();
params.put("term", term);
try (Session session = driver.session();
Transaction tx = session.beginTransaction()) {
StatementResult r = tx.run("MATCH (s:Service)-[:EXPOSES]->(e:Endpoint)" +
" WHERE e.path CONTAINS {term} RETURN DISTINCT s.host",
params);
r.forEachRemaining(record -> microservices.add(
new Microservice(record.get("s.host").asString())
));
tx.success();
}
return microservices;
}
Get all microservices which depends on microservice X
GET <host>:8090/v1/microservices/b36e8649-e82e-4795-8ef6-c2d8eb3e6620/dependants -H 'Content-Type: application/json'
@Override
public List<Microservice> findDependants(String microserviceId) {
List<Microservice> microservices = new ArrayList<>();
HashMap<String, Object> params = new HashMap<>();
params.put("uuid", microserviceId);
Driver driver = connector.getDriver();
try (Session session = driver.session();
Transaction tx = session.beginTransaction()) {
StringBuilder sb = new StringBuilder();
sb.append("MATCH (s1:Service {uuid: {uuid}})<-[:CALL]-(s2:Service)");
sb.append(" RETURN s2.host");
StatementResult r = tx.run(sb.toString(), params);
r.forEachRemaining(record -> microservices.add(
new Microservice(record.get("s2.host").asString())
));
tx.success();
}
return microservices;
}
The microserviceId is generate and returned when you send a POST /v1/microservices with swagger_url as body param. Or you can just checkout the uuid param on Neo4j dashboard if you have executed the fetch_db.sh.
Final Thoughts
It is important to mention that all queries can be easily added using the Cypher query language. "Cypher is a declarative graph query language that allows for expressive and efficient querying and updating of the graph store.".
In addition, I saw spring-data-neo4j allows you to create multiple labels for the same node if you create a parent class. So, all parent classes are added as labels for a node. It is important, because adding more labels to a node means that you can represent more information and ask different questions.
I did not planned to use multiple labels for the same node, but if I had to, I did not want to build a inheritance structure just to represent that. I know it is the logical and OO alternative, but it is also more code to test and maintain. So I decided to try the Java Driver for Neo4J instead.
Another point about using the Java Driver is that you can write your own traversal algorithms for the graph. This might be a good idea when you have a more complex graph and you really know some shortcuts in the model to get faster results than using cypher queries. At the moment, Service-Endpoint graph is pretty simple. Cypher query can solve all my problems, but if I need something more elaborated I can easily implement a new Repository with custom traversal routines.
To connect to Neo4J with Java Driver I created a custom connector which starts the connection with my local Neo4J instance and tests if it is possible to open new sessions. Also, it closes the connection when the app is terminated.
The connector can be a singleton and shared between your services. However, you need to start a new session whenever you need to send a command to Neo4J. You also need to close the session after the work is done. The session creation is thread safe and you can see the sample connector bellow:
import org.apache.log4j.Logger;
import org.neo4j.driver.v1.Driver;
import org.neo4j.driver.v1.GraphDatabase;
import org.neo4j.driver.v1.Session;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
@Component
public class Neo4JConnector {
private static final Logger LOG = Logger.getLogger(Neo4JConnector.class);
private Driver driver;
@PostConstruct
public void init() {
this.driver = GraphDatabase.driver("bolt://localhost");
ping();
LOG.info("Graph DB started");
}
private void ping() {
Session session = this.driver.session();
session.isOpen();
session.close();
}
@PreDestroy
public void terminate() {
driver.close();
LOG.info("Graph DB terminated");
}
public Driver getDriver() {
return driver;
}
}
Even if you want to send cypher queries to Neo4J you do need to open a transaction for that. Otherwise your cypher query will not work.
Well, this is the basic structure for the Vacuum API. We are able to register and extract some information about the dependency graph of our services architecture, see the graph on Neo4J dashboard and easily add new queries or even another db. However, I know there is a ton of work to be done yet and many things here can be improved. I am happy with the solution so far and I wish I had more time to implement other queries before the hackathon deadline. The main idea is in place and I am planning to continue with it as a side project. Let's see how it goes.
Future work
- Add more queries
- Document Vacuum API with Swagger.io
- Add authentication for Vacuum API,
- Enable Neo4J authentication and implement it on Vacuum API
- Create the Unit & IT Tests (Neo4J provides a test db for your IT tests)
- Improve DDD
- Add Java DOCs


Comments
comments powered by Disqus